LoRA Fine-Tuning BitNet b1.58 LLMs on Heterogeneous Edge GPUs via QVAC Fabric













Tether announced a breakthrough in AI model training with the launch of the world’s first cross-platform LoRA fine-tuning framework for Microsoft’s BitNet models (1-bit LLMs). This new capability, part of QVAC Fabric, dramatically reduces memory and compute requirements, enabling billion-parameter language models to be fine-tuned on everyday hardware, including laptops, consumer GPUs, and modern smartphones.
The framework offers cross-platform LoRA fine-tuning support for BitNet models across heterogeneous consumer GPUs including AMD, Apple M3 Pro (GPU) and others.
This marks the first successful demonstration of BitNet fine-tuning on mobile GPUs (Adreno, Mali, Apple Bionic GPU). Users can fine-tune 125M-parameter BitNet models in ~10 minutes on a Samsung S25. For 1B model, fine-tuning ~300 documents (~18k tokens) completes in 1 hour 18 mins on the Samsung S25 (Adreno GPU) and 1 hour 45 minutes on the iPhone 16. Pushing the devices to their limit, our team was able to finetune models up to 13B on the iPhone 16.
The BitNet architecture implementation demonstrates the capability to fine-tune models that are ~2 times larger on edge devices compared to Q4 non-BitNet models, showcasing the memory advantage of the BitNet architecture.
It was also demonsrated that inference of a Bitnet model is significantly faster, ranging from 2.1 to 11.3 times, on edge GPUs compared to CPUs across leading flagship devices, including the Samsung S25, Google Pixel 9, and iPhone 16.
Our benchmark shows that the BitNet-1B (TQ1_0) model uses up to 77.8% less VRAM than Gemma-3-1B (F16) and 65.6% less VRAM than Qwen3-0.6B (F16). This substantial reduction in memory usage makes it significantly more feasible to deploy larger models on memory-constrained edge devices. Further reinforcing this advantage, despite having 3.25 times more parameters (13B vs. 4B), BitNet-13B (TQ1_0) uses 29% less VRAM (2,789 MB) than a 4-bit quantized Qwen3-4B (Q4) model. This breakthrough enables 13B-scale models to run on edge hardware that previously struggled with 4B quantized models without the need for additional memory or hardware upgrades.
We accelerate open-source development and innovation by releasing Multi-Platform Binaries and a collection of Fine-tuned Model Adapters. The QVAC-fabric-llama.cpp is also open source to enable developers to extend the solution to additional LLM architectures.
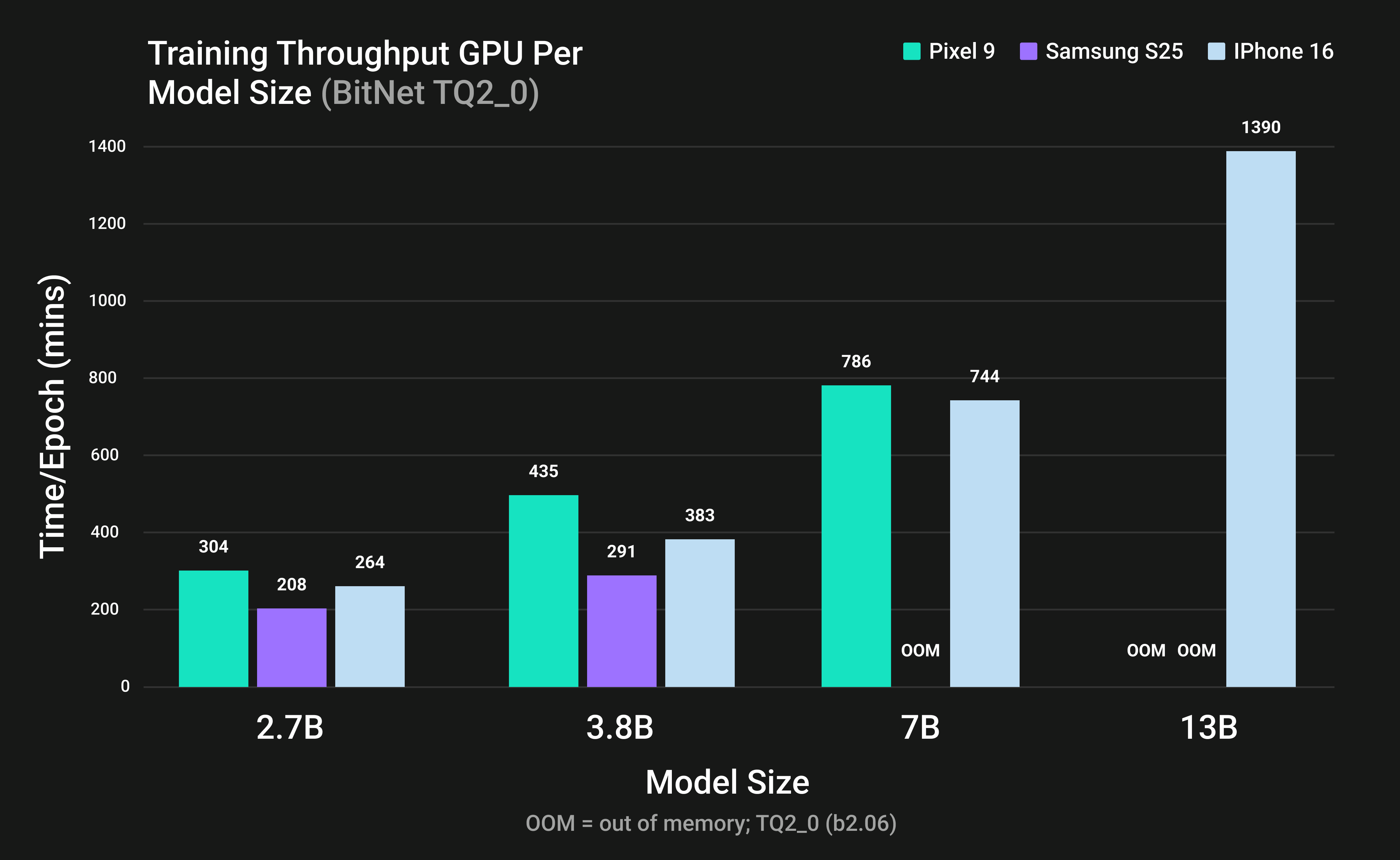 Figure 1: Training throughput of BitNet LLMs on mobile GPUs using TQ2_0 format.
Figure 1: Training throughput of BitNet LLMs on mobile GPUs using TQ2_0 format.
Overview
This is the second chapter of QVAC's ongoing commitment to open-source innovation, following the successful launch of our pioneering work, Edge-First Generalised Fine-Tuning Framework for Heterogeneous GPUs.
We highly encourage readers to examine the first release, QVAC-fabric-llm's LoRA fine-tuning [1]. In that foundational work, we unveiled a robust, unified framework that was meticulously designed to simplify the complex process of fine-tuning large (LLMs) and small language models (SLMs), including the crucial step of instruction-tuning. The framework is compatible with popular and state-of-the-art models such as Qwen3 and Gemma3.
A core philosophy of our initial release, which continues to inform this second installment, is the edge-first approach. This means our solutions are architected to perform optimally on a wide variety of heterogeneous GPU architectures. This commitment ensures maximum compatibility and performance across different across heterogeneous desktop and mobile GPUs (i.e., AMD, Intel, NVIDIA, Adreno, Mali, Apple) using Vulkan and Metal backends.
The framework supports fine-tuning both with and without Low-Rank Adaptation (LoRA) [2], providing flexibility for developers targeting diverse hardware constraints and performance requirements. This new installment specifically addresses Microsoft's BitNet b1.58 [3], an architecture characterized by its low-bit precision and focus on efficient LLM inference on edge devices and consumer GPU hardware.
We introduce the inaugural GPU backend for BitNet b1.58, which facilitates fully lossless ternary inference and LoRA fine-tuning across heterogeneous GPU architectures. We extend llama.cpp with Vulkan-accelerated kernels and dynamic tiling to achieve multi-fold increases in speed and reductions in energy consumption across both desktop and mobile GPUs, while strictly maintaining bit-exact equivalence with CPU results.
🚀 Access QVAC-fabric-llm-bitnet Finetuning Binaries
Access the first truly cross-platform LoRA BitNet fine-tuning solution for Large Language Models
🔗 Get access nowCopyright Complaints: We will take appropriate actions in response to notice of copyright infringement. If you believe your work has been used or copied in a manner that infringes upon your intellectual property rights, please email data-apps@tether.io, identifying and describing both the copyrighted work and alleged infringing content to file a notice of infringement.
Introduction
The growing demand for high-performing Large Language Models (LLMs) has driven continuous scaling of model architectures, leading to substantial increases in computational and memory requirements. As a result, LLM training and inference are typically limited to clusters of high-end GPUs or TPUs, since edge devices and consumer GPUs have constrained memory capacity. Because memory transfer costs often exceed computation costs [4], model compression through quantization has become an effective approach for accelerating inference and fine-tuning.
BitNet introduced an extreme quantization scheme that represents weights using only 1.58 bits [3]. The BitNet architecture matches the Transformer architecture except that it replaces the full-precision linear layers in the Multi-Head Attention and Feed-Forward Networks in transformer architecture with a new layer called the BitLinear layer. The BitLinear layer contains ternary weights instead of full-precision floating-point weights. Before full precision input enters the BitLinear layer, the input is quantized to ternary bits with values -1, 0, and 1. BitNet introduced a promising architecture to lower computing requirements for inference and fine-tuning while maintaining high performance. Currently, Bitnet.cpp subsequently enabled lossless BitNet inference on CPUs. However, BitNet has not previously exploited the massively parallel capabilities of edge GPUs, which are significantly more efficient than CPUs for machine learning inference and fine-tuning.
This release presents the world’s first framework to enable BitNet fine-tuning with Low-Rank Adaptation (LoRA) on GPUs. Built on llama.cpp with a Vulkan backend, the framework supports BitNet and LoRA fine-tuning across heterogeneous consumer GPUs. By extending BitNet to GPUs, the framework enables fine-tuning on edge devices and achieves substantial performance improvements over CPU-based implementations.
Methodology
Datasets
To evaluate our fine-tuning framework, we selected one dataset that stresses different training scenarios while remaining lightweight enough for on-device experimentation:
- Structured Q&A (Biomedical Yes/No Questions): This dataset is derived from PubMedQA and focuses on domain-specific instruction tuning.
A biomedical yes/no/maybe Q&A dataset with explanatory answers was curated from PubMedQA [5] (297 samples, 18K tokens) to simulate a classification-style instruction-following task.
The dataset was used for instruction fine-tuning, where each example was formatted as a user question and an assistant answer, and training was performed with a masked loss applied only to the assistant’s response tokens. Data were stratified into training and evaluation splits, tokenized, truncated, and padded to 512 tokens, then exported as JSONL with a chat-style template when applicable.
Target devices
We evaluated a cross-platform fine-tuning system on three representative mobile and edge devices: Samsung Galaxy S25, Google Pixel 9, and Apple iPhone 16. These devices span major mobile GPU architectures (Adreno, Mali, and Apple A-series GPUs) and were selected to reflect realistic deployment environments for on-device learning and inference.
A custom Vulkan backend integrated into llama.cpp was used to execute the BitNet b1.58 ultra-low-bit large language model. Experiments covered both supported BitNet weight formats (TQ2_0 and TQ1_0), which are decoded on the fly inside GPU shaders while preserving bit-exact, lossless inference behavior across all supported hardware. Identical workloads were executed on CPU and GPU for inference implementations. For fine-tuning, only the GPU was tested. Inference was measured using tokens per second and fine-tuning throughput in time per epoch.
GPU vs CPU Fine-Tuning
Fine-tuning was performed using Low-Rank Adaptation (LoRA), with the 1.58-bit BitNet base weights kept frozen. Trainable low-rank adapters were inserted into the transformer layers. The LoRA operation in BitNet functions similarly to other models, in which the weights in the adapters are in FP16 precision. Unless otherwise specified, a LoRA rank of 8 was used, with initialization scaled by an alpha value of 16.
Training followed a standardized configuration across all devices and tasks:
- AdamW optimizer
- Linear learning-rate decay
- Maximum sequence length of 512 tokens
- Global batch size of 512 tokens per optimization step
- Micro-batching on devices with limited memory capacity
For instruction tuning, a masked loss was applied, excluding system and user tokens from the loss computation. Gradients were computed only on assistant response tokens, aligning with standard supervised instruction-tuning practices.
GPU vs CPU Inference
Inference benchmarking was performed using llama-cli with a fixed input prompt of 13 tokens, a context window of 512 tokens, and a deterministic random seed (42). Each benchmark run generated 256 output tokens, was repeated 5 times, used GPU acceleration with 99 layers offloaded, and had flash attention disabled to ensure consistent and reproducible measurements. Identical decoding settings were used for CPU and GPU runs to isolate raw generation throughput. Deterministic decoding strategies (e.g., greedy decoding or fixed random seeds) ensured identical token sequences across runs, allowing direct performance comparison between execution backends.
GPU Acceleration Techniques
Mobile and integrated GPUs impose strict limits on shader complexity, buffer sizes, and indexing ranges, which can cause large matrix operations to exceed hardware constraints. To address this, dynamic tiling was introduced in Vulkan compute shaders. Large matrix multiplications and update operations are automatically split into smaller tiles that fit within device-specific limits, with partial results accumulated sequentially.
Unified Vulkan Backend
A single Vulkan compute backend was used to support both training and inference across desktop, integrated, and mobile GPUs. Vulkan shaders were employed for both forward and backward passes, enabling a unified codebase across diverse hardware platforms. This design ensures consistent numerical behavior and simplifies cross-platform deployment.
What is TQ1_0 and TQ2_0
The BitNet implementation in llama.cpp uses TQ1_0 and TQ2_0 formats to load the ternary model weights. TQ1_0 is 1.69 bits per ternary weight, while TQ2_0 is 2.06 bits per ternary weight [6].
Results
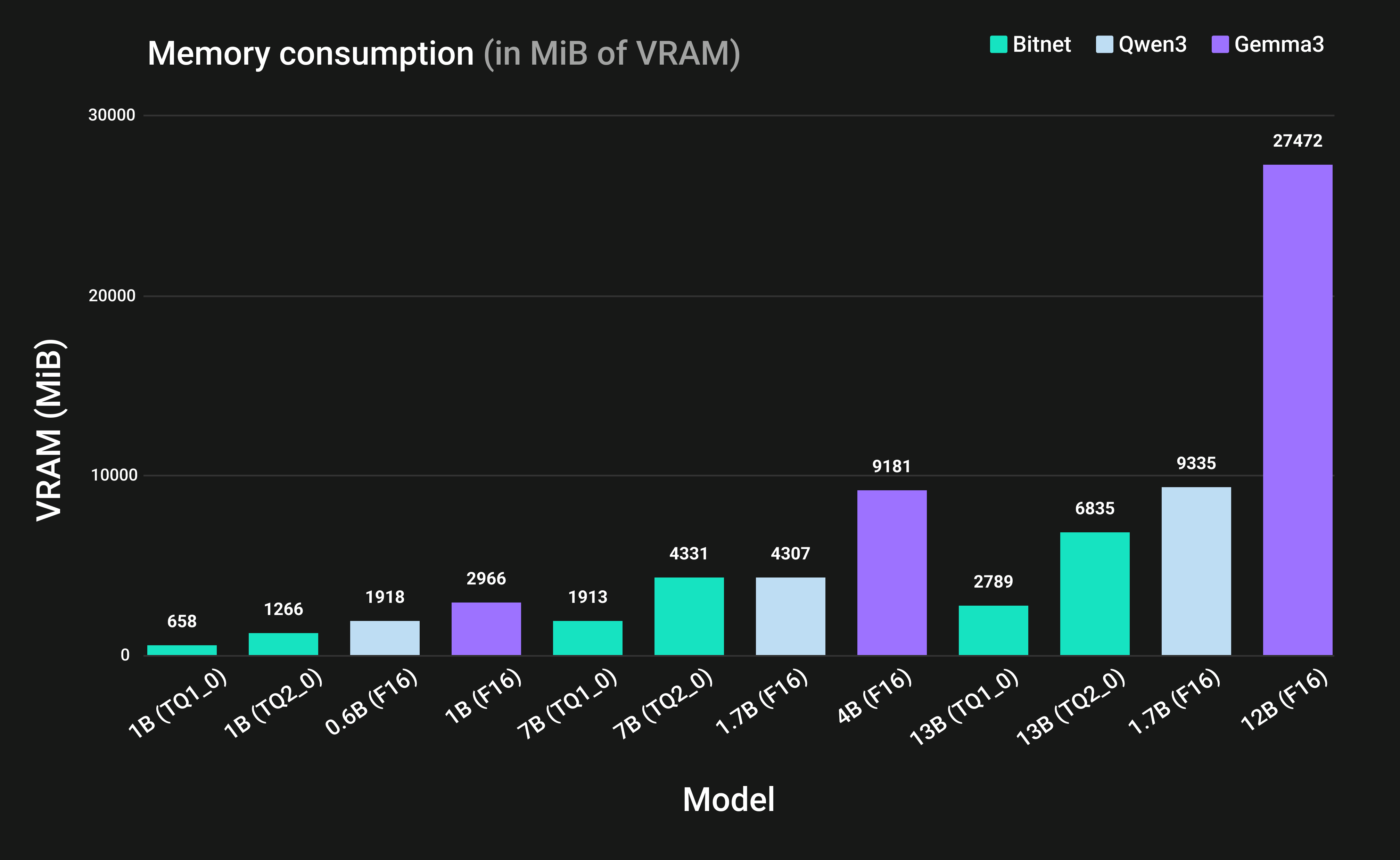 Figure 2: GPU memory footprint of BitNet versus frontier full-precision models.
Figure 2: GPU memory footprint of BitNet versus frontier full-precision models.
Memory Reduction via Ternary Quantization
We compared the memory usage of BitNet under TQ1_0 and TQ2_0 with FP16 implementations of Gemma3 and Qwen3 across multiple model sizes. As shown in Figure 2, BitNet demonstrates a strong capability to reduce hardware requirements by substantially lowering the memory footprint. Moreover, Figure 2 also showed that BitNet has a lower memory footprint compared to other models, even when having a high parameter count.
The BitNet 1B model in the TQ1_0 format requires approximately 614 MiB of VRAM, less than half of the 1,536 MiB required by the smaller Qwen3-0.6B model in FP16. At larger scales, the BitNet-2.7B model uses only 1,228 MiB, yielding a memory footprint nearly 3.5 times smaller than the Qwen3-1.7B model, which requires 4,403 MiB. These results demonstrate that, for small to mid-sized deployments, ternary architectures enable equivalent reasoning capabilities within the same hardware constraints that previously limited models to sub-billion parameter sizes on memory-constrained devices.
Another finding is that TQ1_0 quantization substantially reduces memory usage compared to TQ2 and higher-precision formats. TQ1_0 uses approximately 1.6 bits per weight, compared to 2 bits for TQ2_0. As a result, a 7B BitNet model requires about 1.9 GB of VRAM with TQ1_0, versus roughly 4.3 GB with TQ2_0, nearly a 2 times reduction. On a Samsung S25 GPU, the 7B model could not be loaded with TQ1_0 or TQ2_0 due to memory allocation constraints. On an iPhone 16, the model ran in both formats, with TQ1_0 using ~44% of the memory required by TQ2_0.
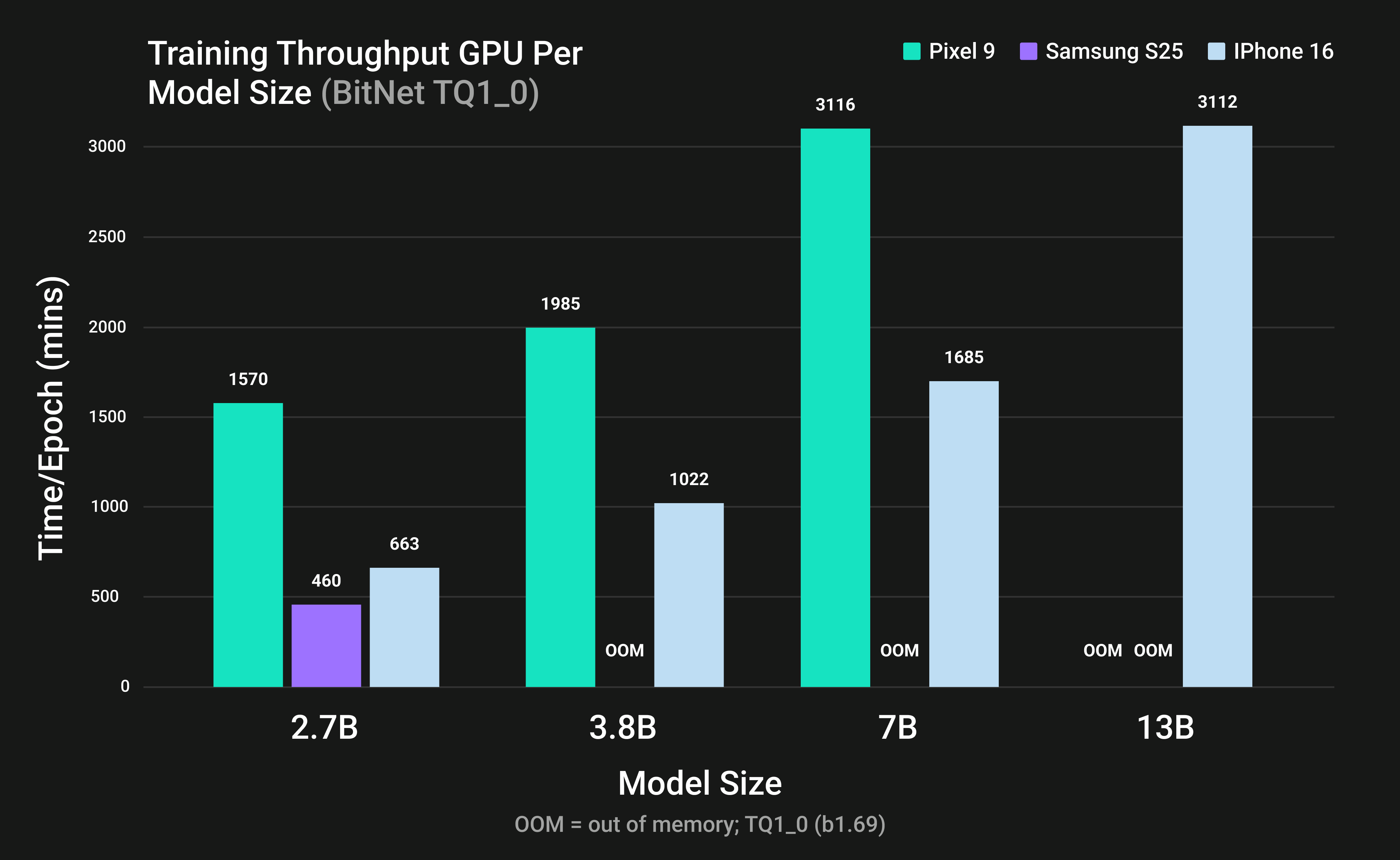 Figure 3: Training throughput of BitNet LLMs on mobile GPUs using TQ1_0 format.
Figure 3: Training throughput of BitNet LLMs on mobile GPUs using TQ1_0 format.
Fine-Tuning Memory Efficiency
The memory efficiency of the BitNet b1.58 architecture is the key enabler of on-device inference and fine-tuning. Its extreme quantization strategy dramatically reduces VRAM requirements compared to standard FP16 models. BitNet b1.58 makes fine-tuning multi-billion-parameter models feasible.
Figures 3 and 4 present fine-tuning performance across mobile GPUs and model sizes, with time per epoch on the y-axis and model size on the x-axis. All mobile GPUs are able to perform fine-tuning for BitNet 2.7B. The results show that for all models, the iPhone 16 can fine-tune 13B-parameter models using both TQ1_0 and TQ2_0 formats, whereas the Pixel 9 and Samsung S25 lack sufficient memory for this task. This finding shows that even a memory-constrained mobile device, such as the iPhone 16, is able to perform fine-tuning on a 13B parameter model. These results demonstrate the practicality of LLM fine-tuning on mobile platforms and confirm that the extreme memory efficiency of BitNet b1.58 enables successful LoRA fine-tuning of 13B-parameter models on consumer hardware.
Fine-Tuning: TQ1_0 vs TQ2_0
Figures 3 and 4 demonstrate that TQ2_0 is substantially faster than TQ1_0 during fine-tuning. For example, on Pixel 9 with BitNet 2.7B, fine-tuning required 1570 minutes using TQ1_0 but only 304 minutes using TQ2_0, indicating that TQ1_0 takes approximately five times longer per epoch. Overall, TQ2_0 consistently outperforms TQ1_0 in fine-tuning speed across all evaluated devices and models.
Inference: TQ1_0 vs TQ2_0
With the default CPU-based llama.cpp implementation, TQ2_0 quantization was generally expected to be faster than TQ1_0. However, our Vulkan-based GPU backend flips this trend; we observed TQ1_0 being comparable to TQ2_0 (but a bit slower) on mobile GPUs in most cases and significantly faster than TQ2_0 for iPhone 16. The key advantage of TQ1_0 is its smaller memory footprint, enabling larger models to run on smartphones. For example, at 1B, TQ1_0 uses ~600 MB, and TQ2_0 ~1.3 GB.
Inference: GPU vs. CPU
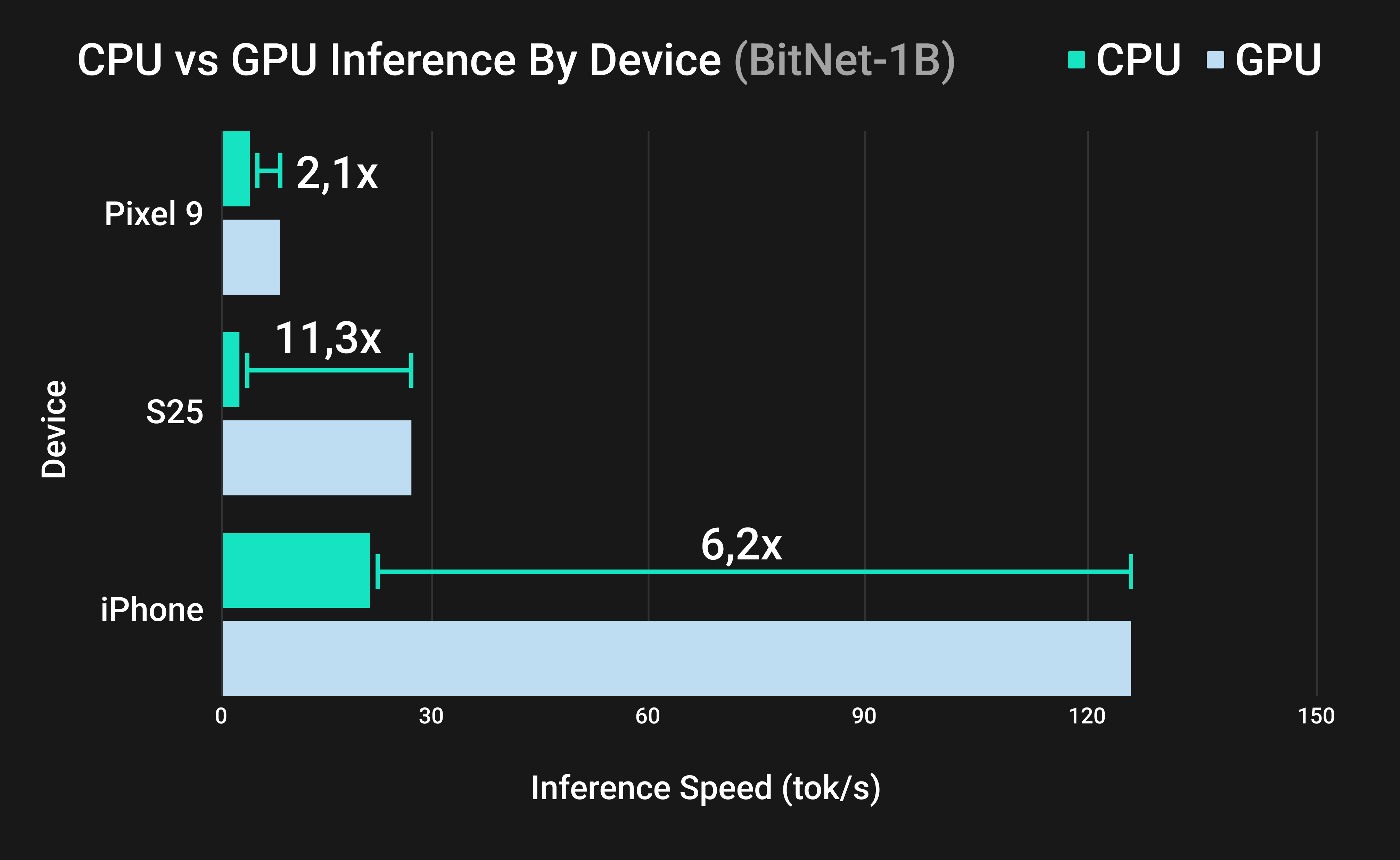 Figure 4: GPU versus CPU inference speeds (BitNet-1B) across flagship smartphones.
Figure 4: GPU versus CPU inference speeds (BitNet-1B) across flagship smartphones.
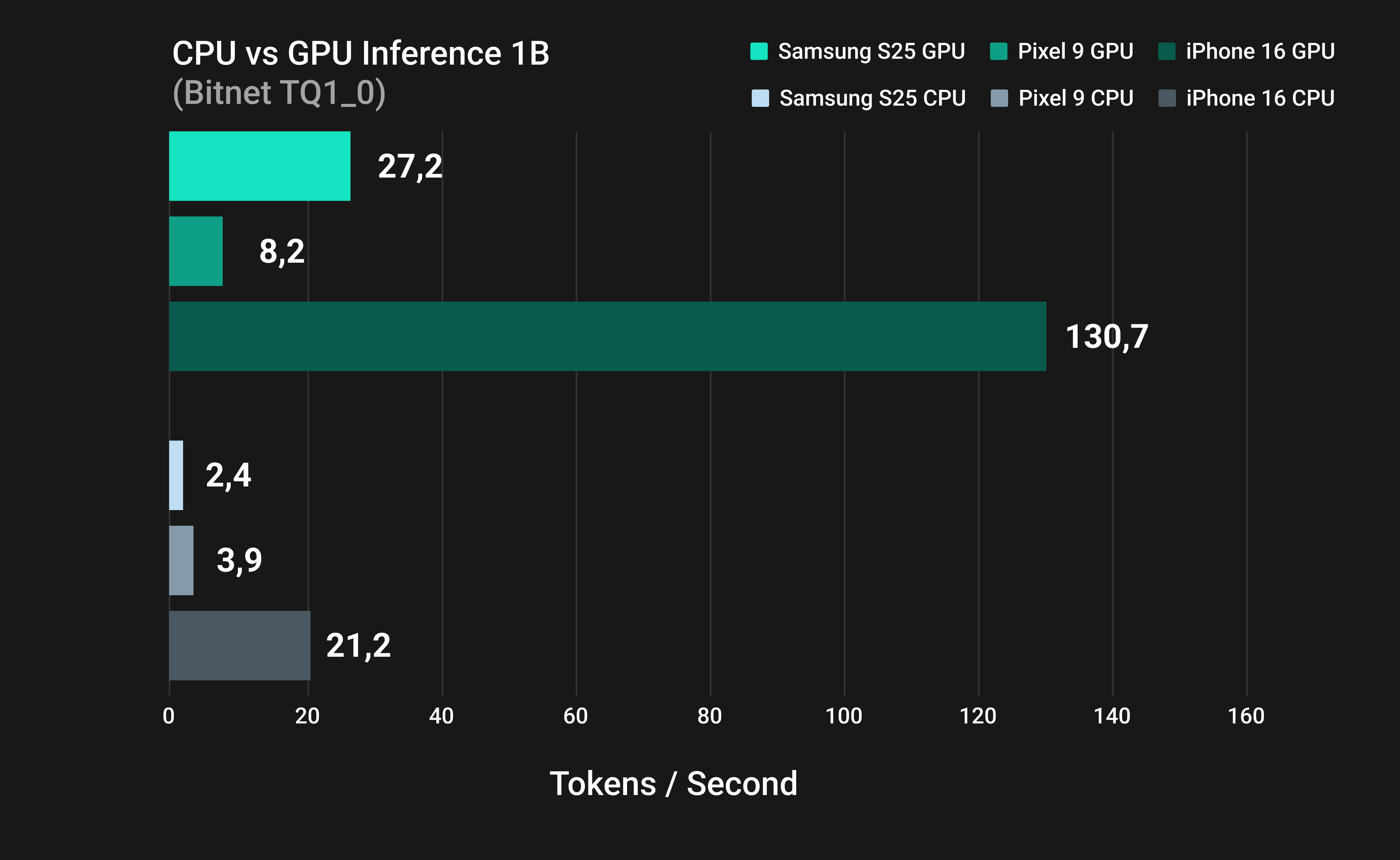 Figure 5: GPU versus CPU inference comparison for 1B models
Figure 5: GPU versus CPU inference comparison for 1B models
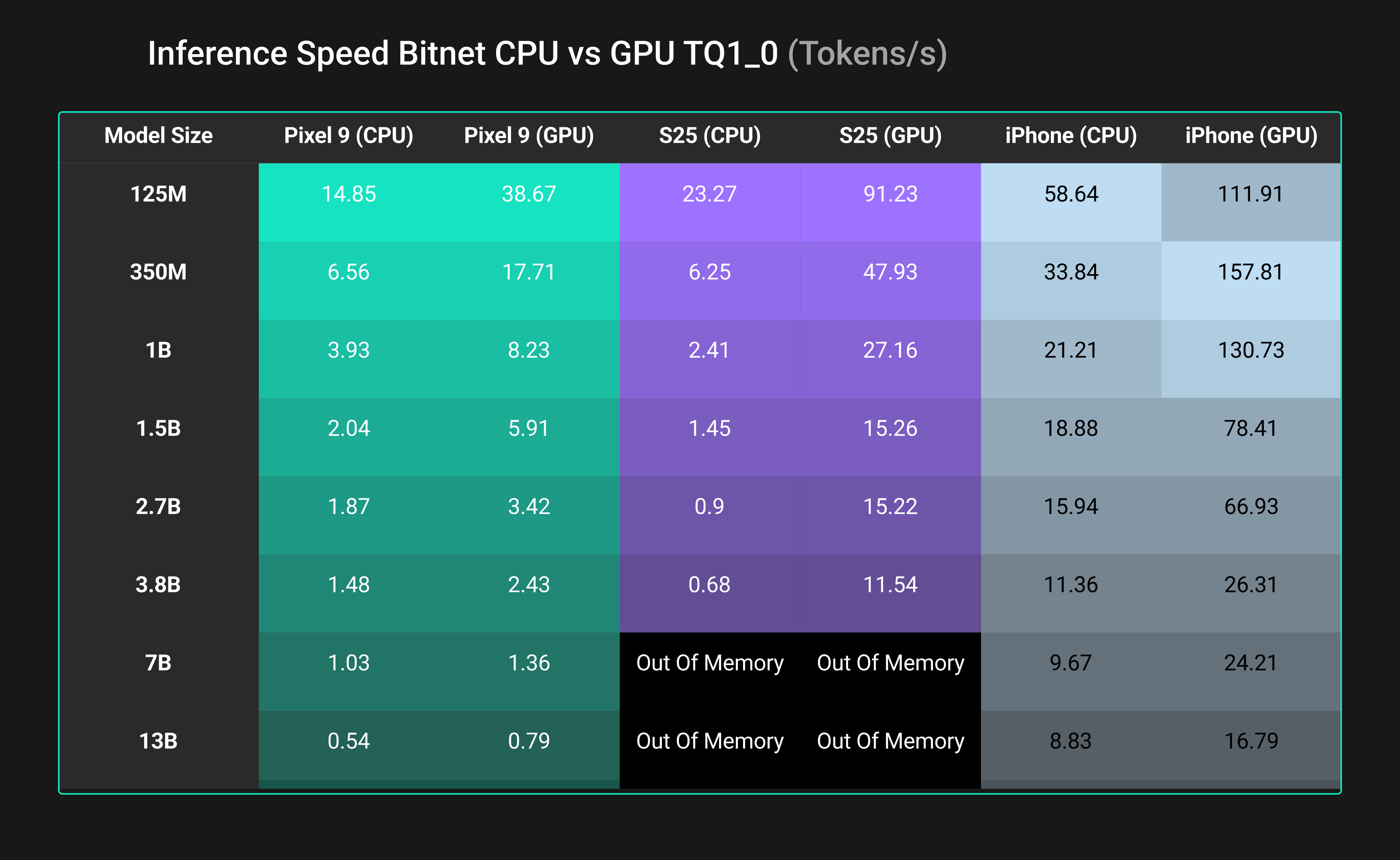 Figure 6: GPU versus CPU inference comparison for all model sizes
Figure 6: GPU versus CPU inference comparison for all model sizes
Figure 5 compares the inference speed of BitNet across multiple devices, showing the performance of CPU inference versus GPU inference. Figure 6 suggests that across all tested devices, offloading inference to the GPU yielded substantial speedups in tokens per second compared to CPU-only execution. For example, on the iPhone 16, the A17 GPU generated text over 6 times faster than the CPU for a 1B parameter model for both TQ1_0 and TQ2_0 (TQ1: 130.7 vs 21.2 tokens/sec).
The Adreno GPU in the Samsung S25 was even more effective, achieving up to 11 times higher throughput than its CPU at 1B for both TQ1_0 and TQ2_0 (TQ1: 27.2 vs 2.4 tokens/sec).
Even the Pixel 9’s Mali GPU delivered roughly a 2 times speedup over CPU (~8.2 vs 3.9 tokens/sec at 1B), despite being a less powerful GPU. These gains mean that on-device text generation can be significantly accelerated by utilizing mobile GPUs, making real-time inference feasible on modern phones.
Inference Accuracy
Finally, we evaluate inference accuracy using the same lossless criterion employed in the BitNet CPU study. Across all tested GPUs, our Vulkan-based TQ2_0 and TQ1_0 kernels achieve very similar accuracy. The results mirror those of the TL1 and TL2 CPU kernels in bitnet.cpp and confirm that ternary inference on GPU preserves the lossless property of BitNet b1.58. No differences were observed. This demonstrates that the Vulkan implementation correctly reproduces the semantics of the BitNet architecture, ensuring that lossless inference is not limited to the CPU environment but extends naturally to GPU platforms.
Quantization Format Impact on Performance
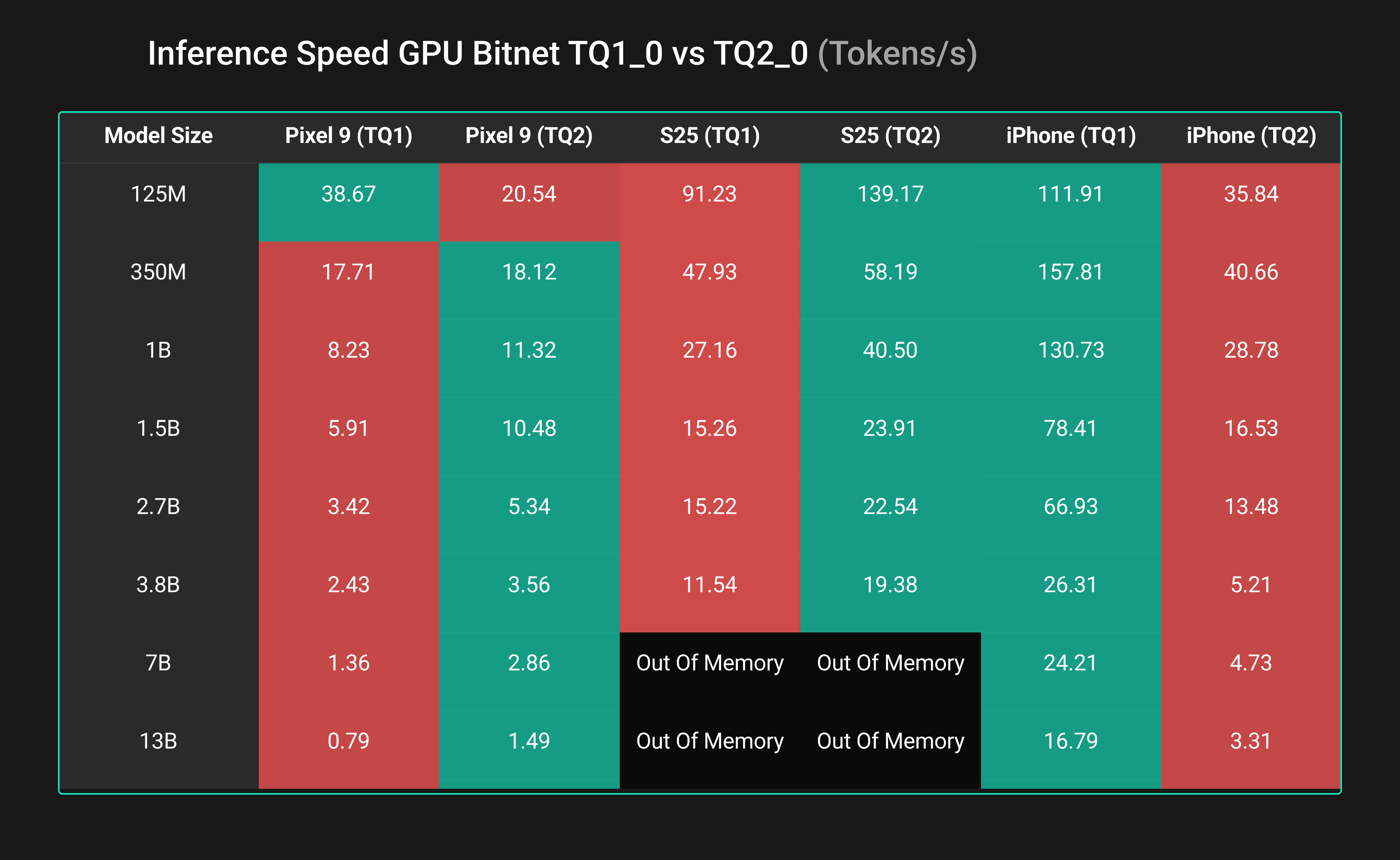 Figure 7: This table shows the inference performance for BitNet comparing the TQ1_0 format and the TQ2_0 format. Green indicates higher performance, and red indicates lower performance
Figure 7: This table shows the inference performance for BitNet comparing the TQ1_0 format and the TQ2_0 format. Green indicates higher performance, and red indicates lower performance
Figure 7 shows the benchmark of inference performance for BitNet across various mobile devices and model sizes, comparing the inference throughput for TQ1_0 versus TQ2_0 format. Table 6 suggests that the quantization format strongly affects inference throughput. On mobile GPUs, results varied by device. Apple’s GPU strongly favored TQ1_0, delivering 4 to 5 times higher throughput on the iPhone 16 across model sizes. In contrast, the S25’s Adreno GPU favored TQ2_0, while the Pixel 9’s Mali GPU showed mixed behavior depending on model size. While TQ1_0 can be substantially faster than TQ2_0, especially on Apple GPUs, indicating that more compact quantization does not necessarily reduce GPU throughput across devices.
Conclusions
This work successfully extends the QVAC-fabric-llm [1] framework by introducing QVAC-fabric-llm-bitnet, achieving the world's first vendor-agnostic BitNet fine-tuning solution on consumer GPUs and edge devices. We have provided compelling evidence that edge GPUs offer superior performance over CPUs for BitNet fine-tuning, pushing the boundaries of what is possible on devices like the Samsung S25, Google Pixel 9, and iPhone 16. Our benchmarks demonstrated the ability to fine-tune BitNet models of up to 13B parameters (TQ1_0) on mobile devices. Moreover, BitNet models show significantly lower memory consumption compared to their FP16 counterparts (Qwen3 and Gemma3). By publicly releasing multi-platform binaries, fine-tuned model adapters, and the source code, we aim to accelerate open-source development and innovation in the field of low-bit LLMs.
References
- [1] SN, S., Nambiar, A., Lambert, P., Gritta, M., & Nurman, A. (2025, December 1). An edge-first generalized LLM LoRA fine-tuning framework for heterogeneous GPUs. Hugging Face Blog. https://huggingface.co/blog/qvac/fabric-llm-finetune
- [2] Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L. and Chen, W. (2022) ‘LoRA: Low-rank adaptation of large language models’, in International Conference on Learning Representations (ICLR). https://arxiv.org/abs/2106.09685
- [3] Ma, S., Wang, H., Ma, L., Wang, L., Wang, W., Huang, S., Dong, L., Wang, R., Xue, J., & Wei, F. (2024). The era of 1-bit LLMs: All large language models are in 1.58 bits. arXiv preprint arXiv:2402.17764. https://arxiv.org/abs/2402.17764
- [4] Dao, T., Fu, D. Y., Ermon, S., Rudra, A., & Ré, C. (2022). FlashAttention: Fast and memory-efficient exact attention with IO-awareness. arXiv preprint arXiv:2205.14135. https://arxiv.org/abs/2205.14135
- [5] Jin, Q., Dhingra, B., Liu, Z., Cohen, W., & Lu, X. (2019, November). Pubmedqa: A dataset for biomedical research question answering. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) (pp. 2567-2577).
- [6] Wang, J., Zhou, H., Song, T., Cao, S., Xia, Y., Cao, T., Wei, J., Ma, S., Wang, H., & Wei, F. (2025). Bitnet.cpp: Efficient edge inference for ternary LLMs. arXiv preprint arXiv:2502.11880. https://arxiv.org/abs/2502.11880




